
hadoop dfs命令之HelloWorld
浏览: 2876
2017年12月24日
前面我们写了一个Hadoop程序,并让它跑起来了。但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce。没错,上一节我们写了一个MapReduce的HelloWorld程序,那这一节,我们就也学一学DFS程序的编写。DFS 是什么,之前已经了解过,它是一个分布式文件存储系统。不...
hadoop mapreduce的思想(含代码例子)
浏览: 2669
2017年12月09日
之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果。现是得开始稍微更深入地了解hadoop了。Hadoop包含了两大功能DFS和MapReduce, DFS可以理解为一个分布式文件系统,存储而已,所以这里暂时就不深入研究了,等后面读了其源码后,再来深入分析。 所以这里主...

hadoop自定义输入输出格式和数据类型
浏览: 3535
2017年12月09日
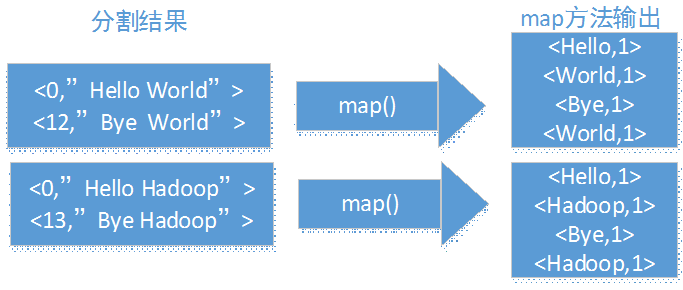
从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤:1.输入(input):将输入数据分成一个个split,并将split进一步拆成<key, value>。2.映射(map):根据输入的<key, value>进生处理,3.合并(combiner):合并中间相两同的ke...
hadoop项目案例代码实现Hello World
浏览: 3008
2017年12月02日
整个Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA。在linux下开发JAVA还数eclipse方便。1、下载进入官网:http://eclipse.org/downloads/。找到相应的版本进行下载,我这里用的是eclipse-SDK-3.7.1-linux...
hadoop分布式环境搭建步骤详解
浏览: 2242
2017年11月28日
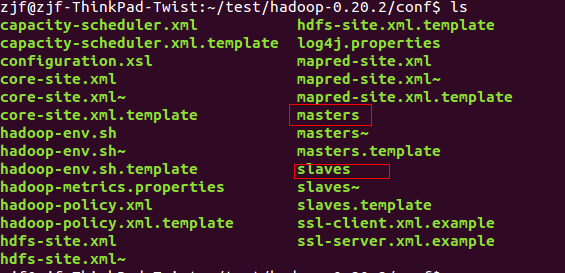
前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下。在这里,我们采用这样的策略来模拟环境,我们使用3台ubuntu机器,1台为作主机(master),另外2台作为从机(slaver)。同时,这台主机,我们就...

Hello Word 实例实现
浏览: 2709
2017年11月27日
上一章中,我们把hadoop下载、安装、运行起来,最后还执行了一个Hello world程序,看到了结果。现在我们就来解读一下这个Hello Word。OK,我们先来看一下当时在命令行里输入的内容:$mkdir input$cd input$echo "hello world">test1.tx...

环境搭建
浏览: 4006
2017年10月13日
一、Hadoop是什么一个分布式系统基础架构,由Apache基金会所开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有...
Hadoop 监控
浏览: 2264
2017年09月01日
Log yarn.log-aggregation-enable=true如果显示错误,则日志存储在节点管理器运行节点上。当聚集启用时所有日志进行汇总,任务完成后转移到HDFS。Hadoop集群性能监控Ganglia, Nagios使用Hadoop工具 Ambari管理集群
Hadoop 配置
浏览: 2250
2017年09月01日
有两种配置文件:一种是-default.xml(只读,默认的配置)core-site.xml 配置公共属性hdfs-site.xml 配置HDFSyarn-site.xml 配置YARNmapred-site.xml 配置MapReduce配置文件应用的顺序:1、在JobConf中指定的2、客户...
Hadoop 安装
浏览: 2193
2017年08月31日
单节点安装所有服务运行在一个JVM中,适合调试、单元测试伪集群所有服务运行在一台机器中,每个服务都在独立的JVM中,适合做简单、抽样测试多节点集群服务运行在不同的机器中,适合生产环境配置公共帐号方便主与从进行无密钥通信,主要是使用公钥/私钥机制所有节点的帐号都一样在主节点上执行 ssh-keyg...
Hadoop 测试
浏览: 2313
2017年08月31日
MRUnit单元测试Mapper和Reducer类在内存上独立运行, PipelineMapReduceDriver单线程运行.LocalJobRunner单线程运行, 且仅有一个 Reducer能够启动conf.set("mapred.job.tracker", "local"); conf....
Hadoop IO
浏览: 2141
2017年08月30日
1. 输入文件从HDFS进行读取.2. 输出文件会存入本地磁盘.3. Reducer和Mapper间的网络I/O,从Mapper节点得到Reducer的检索文件.4. 使用Reducer实例从本地磁盘回读数据.5. Reducer输出- 回传到HDFS.串行化传输、存储都需要Writable接口...
4.2:MapReduce Shuffle
浏览: 2031
2017年08月29日
对Map的结果进行排序并传输到Reduce进行处理 Map的结果并不#x662F;直接存放到硬盘,而是利用缓存做一些预排序处理 Map会调用Combiner,压缩,按key进行分区、排序等,尽量减少结果的大小 每个Map完成后都会通知Task,然后Reduce就可以进行处理Map端当Map程序开...
4.2:MapReduce Mapper
浏览: 2120
2017年08月28日
主要是读取InputSplit的每一个Key,Value对并进行处理public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { /** * 预处理,仅在map task启动时运行一次 */ protected voi...
4.1:MapReduce 读取数据
浏览: 2177
2017年08月18日
通过InputFormat决定读取的数据的类型,然后拆分成一个个InputSplit,每个InputSplit对应一个Map处理,RecordReader读取InputSplit的内容给MapInputFormat决定读取数据的格式,可以是文件或数据库等功能1、验证作业输入的正确性,如格式等2、...
Hadoop MapReduce
浏览: 2316
2017年08月16日
简介一种分布式的计算方式指定一个Map(映#x5C04;)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。Patternmap: (K1, V1) → list(K2, V2)combine: (K2, list(...
3.5、YARN Failover失败处理
浏览: 2506
2017年08月14日
失败类型1 程序问题2 进程崩溃3 硬件问题失败处理任务失败1 运行时异常或者JVM退出都会报告给ApplicationMaster2通过心跳来检查挂住的任务(timeout),会检查多次(可配置)才判断该任务是否失效3 一个作业的任务失败率超过配置,则认为该作业失败4 失败的任务或作业都会...
3.4、YARN Container
浏览: 2340
2017年08月14日
1 .基本的资源单位(CPU、内存等)2. Container可以加载任意程序,而且不限于Java3. 一个Node可以包含多个Container,也可以是一个大的Container4. ApplicationMaster可以根据需要,动态申请和释放Containercontainer就...
3.3、YARN ApplicationMaster
浏览: 2145
2017年08月13日
单个作业的资源管理和任务监控具体功能描述:1. 计算应用的资源需求,资源可以是静态或动态计算的,静态的一般是Client申请时就指定了,动态则需要ApplicationMaster根据应用的运行状态来决定2. 根据数据来申请对应位置的资源(Data Locality)3. 向ResourceMa...
3.2、YARN NodeManager
浏览: 2265
2017年08月04日
Node节点下的Container管理1,启动时向ResourceManager注册并定时发&##x9001;心跳消息,等待ResourceManager的指令2,监控Container的运行,维护Container的生命周期,监控Container的资源使用情况3,启动或停止Container...